
Quand les listes s'allongent, il n'est pas rare que l'on trouve plusieurs fois le même enregistrement .......
C'est le moment de faire un peu de nettoyage.
Qu'est-ce qu'un doublon ?
Dans notre cas, c'est avoir le même nom ET le même prénom sur plusieurs lignes.
Une possibilité pour épurer cette liste consiste à trier le tableau en fonction des critères de recherche des doublons. Ensuite on peut balayer le tableau et supprimer les lignes "doublons".
Au bout de 5mn, les yeux se croisent et on commence à chercher un bon prétexte pour faire cela une autre fois.
Par chance (ce n'est sans doute pas uniquement de la chance), Excel propose une fonctionnalité de suppression de doublons. Bien sûr elle n'est pas utilisable tout le temps mais elle suffit souvent..
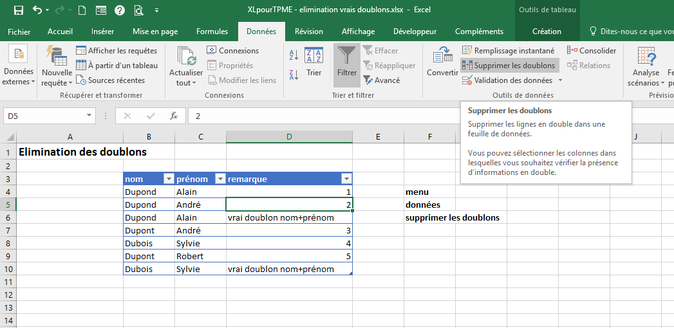
Dans notre exemple, les données sont mises en forme par la commande "mettre sous forme de tableau (c'est pratique, pourquoi s'en priver?).
Il suffit de cliquer sur une cellule du tableau, d'aller dans l'onglet de menu "Données" et de cliquer sur "Supprimer les doublons".

Excel permet alors de choisir les colonnes du tableau qui serviront à la détection des doublons.
Dans notre exemple, la colonne remarque n'est pas incluse dans la recherche: Elle n'est là que pour indiquer le résultat souhaité et valider la démonstration.

Les critères définis, un clic sur Ok et Excel vous annonce ses conclusions.
Par un heureux hasard, 2 doublons sont détectés...

En prime le tableau est réajusté à la longueur des enregistrements restants.
En amélioration continue, c'est le premier "S" de la méthode 5S :
- le SEIRI qui veut dire débarrasser.
- Vous pouvez ensuite passer au SEITO ("Ranger") avec le tri automatique.
- Un coup d'œil pour le SEISO, régler les anomalies.
- S'assurer que "n'importe qui" pourra se débrouiller avec votre oeuvre : le SEIKETSU
- Il ne vous restera plus qu'à tenir propre, le SHITSUKE
Vu comme cela, c'est simple n'est-ce pas?
Un bémol pourtant : cette méthode n'est pas universelle. Le principe "manuel" évoqué en haut de billet permet le contrôle avant la rectification, par exemple sur la colonne "remarque" qui pourrait contenir une information importante sur une ligne qui, à priori, serait considérée comme doublon.

Au lieu de systématiquement corriger, au risque d'oublier, un peu d'anticipation permet de travailler plus fiablement et sereinement.
Dès la saisie, une formule en D1 alerte sur le risque de doublon.
Les possibilités pour une telle formule sont multiples, en voici quelques unes :
si la liste n'est pas sous forme de tableau et que l'on estime qu'elle ne fera jamais plus de 100 lignes (modifiable)
SI(NB.SI.ENS(DECALER($B$3;1;0;100;1);DECALER($B$3; EQUIV("zzz";$B4:$B103;1);0);DECALER($C$3;1;0;100;1);DECALER($C$3; EQUIV("zzz";$C4:$C103;1);0))>1;"Doublon probable";"")
si l'entrée de données se fait sur une ligne du tableau
=SI(NB.SI.ENS(Tableau2[nom];INDIRECT("B" & EQUIV("zzz";$B:$B;1));Tableau2[version];INDIRECT("C" & EQUIV("zzz";$C:$C;1)))>1;"Doublon probable";"")
si l'entrée de données se fait sur la ligne sous le tableau
=SI(NB.SI.ENS($B:$B;INDIRECT("B" & EQUIV("zzz";$B:$B;1));$C:$C;INDIRECT("C" & EQUIV("zzz";$C:$C;1)))>1;"Doublon probable";"")
avec un tableau nommé, en formule matricielle (à valider par les touches ctrl shift entrée) :
=SI(LIGNES(Tableau13[nom])-NB(1/FREQUENCE(EQUIV(Tableau13[nom]&Tableau13[version];Tableau13[nom]&Tableau13[version];0);LIGNE(INDIRECT("1:"&LIGNES(Tableau13[nom])))))>0;"Doublon probable";"")
Avec de l'imagination vous trouverez sans doute plus simple ou plus adapté à vos habitudes. Nous sommes dans un tableau et les combinaisons de fonctions INDEX, EQUIV, DECALER, SOMMEPROD, SOMME.SI, SOMME.SI.ENS ....
offrent sûrement des solutions que je n'ai même pas envisagées.